L'un des principaux problèmes rencontrés lors de la création de ce projet, c'est la détection de l’encodage des pages web qu’on a récoltées. Ces dernières doivent être encodées en UTF-8 (terme que nous essayerons d’expliquer par la suite) si ce n’est pas le cas, les convertir en UTF-8.
Qu’est ce que UTF-8?
On ne peut pas aborder la notion d’UTF-8 sans passer d’abord par la notion l’ASCII et de l'UNICODE.
L’ASCII (American Standard Code for Information Interchange) est un standard américain, utilisé par la plupart des ordinateurs dans le monde, il permet d’associer à chaque caractère ou symbole un numéro. Ces numéros comme on peut le voir sur allant de 0 à 127
Ces numéros comme on peut le voir, sont compris entre 0 et 127. Les numéros inférieur à 33 correspondent aux caractères non-imprimables ce qu'on appelle aussi des codes de contrôle, ils ne s'affichent pas à l'utilisateurs: par exemple le code 10 permet de revenir à la ligne, 32 pour l'espace entre les mots etc. Pour écrire un h minuscule il faut utiliser le nombre 104, pour un J majuscule il faut le nombre 74 et ainsi de suite.
Mais un problème se pose, la table ASCII ne comprend pas les caractères accentués tels que les é, à, è, on a donc inventé l'UNICODE.
UNICODE permet de représenter tous les caractères spécifiques aux différentes langues. Au contraire de l'ASCII, au lieu d'utiliser des codes allant de 0 à 127, il utilise des codes encore plus grands. On retrouve alors des caractères latins (accentués ou non accentués), grecs, arméniens, arabes, hébreux, hiragana etc
Voici donc un exemple de la table de l'arabe sur Unicode:
N'oublions pas de mentionner qu'un caractère d'Unicode prend 2 octets donc deux fois plus de place qu'en ASCII ce qui fait qu'ASCII est beaucoup plus répandu qu'Unicode.
Sachant que la plupart des caractères dans la langue française sont des caractères présents dans l'ASCII, et que les caractères accentués représentent une petite partie seules nécessitent l'Unicode, on a donc pensé à une solution: UTF-8 !
UTF-8 (Universal Character Set Transformation Format - 8 bits) est un codage de caractères très répandu vu sa simplicité: il est codé de 8 à 32 bits ce qui permet de coder un grand nombre de caractères. Il est partout en ASCII et dès qu'on a besoin d'un caractère d'Unicode on utilise un caractère spécial signalant que ce caractère là n'est pas de l'ASCII mais de l'Unicode (on reviendra sur ce point dans la suite de cet article).
Pourquoi avons-nous besoin de pages web en UTF-8?
Comme on l'a mentionné précédemment, l'encodage en UTF-8 prend en compte tous les caractères qui peuvent exister sur le web, et la totalité des navigateurs et des éditeurs de textes le prennent en compte, cela évite ainsi les problèmes d'affichage de caractères dans les textes. Sachant que notre but est d'extraire les textes des URLS récoltés et effectuer des traitements de textes dessus, il faut alors que tous les caractères soient affichés correctement pour permettre l'exploitation de ces ressources, alors la meilleure solution reste celle de convertir tous ces liens en UTF-8 en passant par le détection de l'encodage de chaque URL.
Comment détecter et convertir l'encodage des pages web?
Pour détecter l'encodage d'une page web sur le terminal, on doit d'abord utiliser la commande CURL pour avoir le code retour HTTP. (De manière général, CURL permet de faire des requêtes sur un serveur web via un des protocoles qu'il supporte.)
Les codes HTTP correspondent à des codes de statuts du protocol HTTP l'H'yperText Transfer Protocol, protocole de transfert hypertexte en français, qui permet à un serveur web de transmettre des informations et des pages à un client ou un navigateur web, ces codes sont composés de trois chiffres grace à eux on peut analyser le statut de la page web. Le code 404 par exemple signifie que la page demandée n'existe pas alors que le code 202 signifie que la requête a été réalisée avec succès.
On va pas trop se pencher vers ces code dans notre article, mais ce qui nous intéresse le plus c'est le Charset donné par la requête:
A l'aide de la commande CURL -i , on a pu alors avoir une information située dans ce qu'on appelle le Charset où c'est mentionné l'encodage de la page (UTF-8 pour notre exemple). Charset veut dire l'ensemble des caractères.
Problème
Sur une page web, pour insérer des caractères spéciaux qui ne sont pas comprises sur ASCII, les administrateurs de cette page ont trois choix:
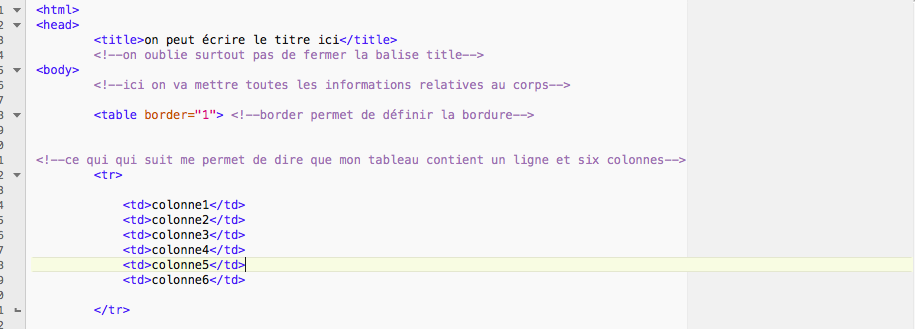
- Utiliser les entités HTML (voire ce lien) pour le caractère qu'on veut insérer. ex: î pour î.
- Ecrire le caractère tel qu'il est et préciser son encodage au Charset dans la balise <head> ex:
<meta charset="UTF-8"> .
3. Travailler directement en UTF-8 sur l'éditeur HTML.
L'un des problèmes qu'on peut rencontrer, c'est le faite que la personne qui a créée le site web a déclaré un faux encodage au Charset, ce qui complique la tâche de détection et de conversion.
On expliquera par la suite dans un article plus détaillé le processus de détection et de conversion de l'encodage des pages web.
Liens utiles:
- Tables Unicode
- Entités HTML
- Charset
>>> To be continued







 La raison est bien expliqué sur notre article "je m'appelle HTML".
La raison est bien expliqué sur notre article "je m'appelle HTML".


 Comme on voit ici, ces trois encodages sont compris dans le seul lien, dans ce cas, on va prendre le premier comme le bon.
Comme on voit ici, ces trois encodages sont compris dans le seul lien, dans ce cas, on va prendre le premier comme le bon.